
Featured Publications
A more complete list of my publications is available here.
A Multifidelity Sim-to-Real Pipeline for Verifiable and Compositional Reinforcement Learning
Cyrus Neary, Christian Ellis, Aryaman Singh Samyal, Craig Lennon, and Ufuk Topcu
The IEEE International Conference on Robotics and Automation (ICRA) 2024.

We propose and demonstrate a compositional framework for training and verifying reinforcement learning (RL) systems within a multifidelity sim-to-real pipeline, in order to deploy reliable and adaptable RL policies on physical hardware. By decomposing complex robotic tasks into component subtasks and defining mathematical interfaces between them, the framework allows for the independent training and testing of the corresponding subtask policies, while simultaneously providing guarantees on the overall behavior that results from their composition. By verifying the performance of these subtask policies using a multifidelity simulation pipeline, the framework not only allows for efficient RL training, but also for a refinement of the subtasks and their interfaces in response to challenges arising from discrepancies between simulation and reality. In an experimental case study we apply the framework to train and deploy a compositional RL system that successfully pilots a Warthog unmanned ground robot.
Franck Djeumou*, Cyrus Neary*, and Ufuk Topcu
The Conference on Robot Learning (CORL) 2023 — oral presentation.
* indicates equal contribution.

We present a framework and algorithms to learn controlled dynamics models using neural stochastic differential equations (SDEs)—SDEs whose drift and diffusion terms are both parametrized by neural networks. We construct the drift term to leverage a priori physics knowledge as inductive bias, and we design the diffusion term to represent a distance-aware estimate of the uncertainty in the learned model’s predictions. The proposed neural SDEs can be evaluated quickly enough for use in model predictive control algorithms, or they can be used as simulators for model-based reinforcement learning. We demonstrate these capabilities through experiments on simulated robotic systems, as well as by using them to model and control a hexacopter’s flight dynamics: A neural SDE trained using only three minutes of manually collected flight data results in a model-based control policy that accurately tracks aggressive trajectories that push the hexacopter’s velocity and Euler angles to nearly double the maximum values observed in the training dataset.
Read More | Paper | Poster | Youtube Video | Data Collection Videos
Compositional Learning of Dynamical System Models Using Port-Hamiltonian Neural Networks
Cyrus Neary and Ufuk Topcu
The Learning for Dynamics and Control Conference (L4DC) 2023.
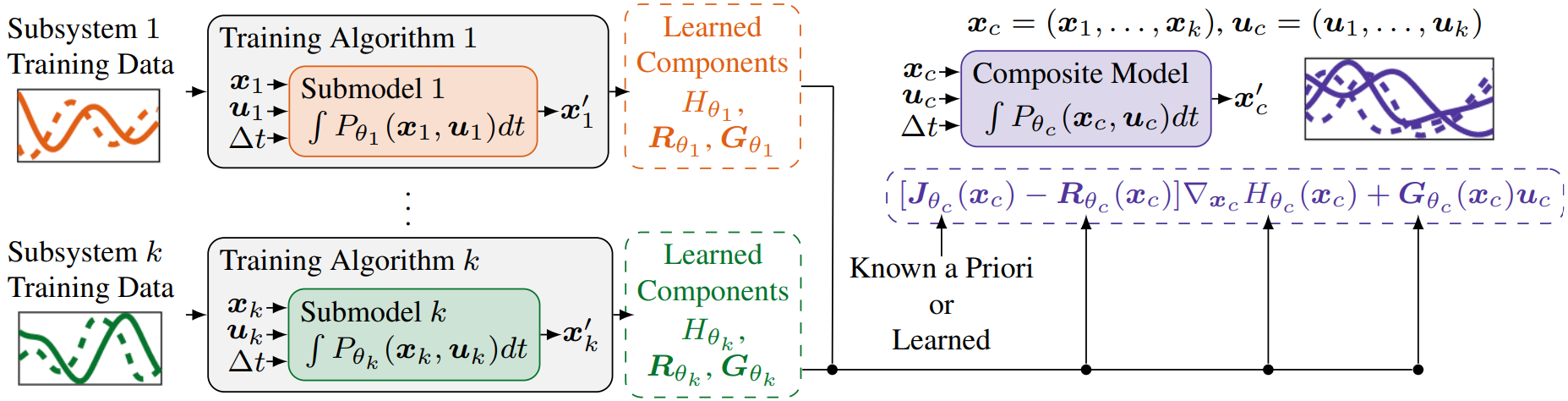
Many dynamical systems – from robots interacting with their surroundings to large-scale multiphysics systems – involve a number of interacting subsystems. Toward the objective of learning composite models of such systems from data, we present i) a framework for compositional neural networks, ii) algorithms to train these models, iii) a method to compose the learned models, iv) theoretical results that bound the error of the resulting composite models, and v) a method to learn the composition itself, when it is not known a prior. The end result is a modular approach to learning: neural network submodels are trained on trajectory data generated by relatively simple subsystems, and the dynamics of more complex composite systems are then predicted without requiring additional data generated by the composite systems themselves. We achieve this compositionality by representing the system of interest, as well as each of its subsystems, as a port-Hamiltonian neural network (PHNN) – a class of neural ordinary differential equations that uses the port-Hamiltonian systems formulation as inductive bias.
Read More | Paper | Poster | Code
Differential Privacy in Cooperative Multiagent Planning
Bo Chen*, Calvin Hawkins*, Mustafa O. Karabag*, Cyrus Neary*, Matthew Hale, and Ufuk Topcu
The Conference on Uncertainty in Aritifical Intelligence (UAI) 2023.
* indicates equal contribution.
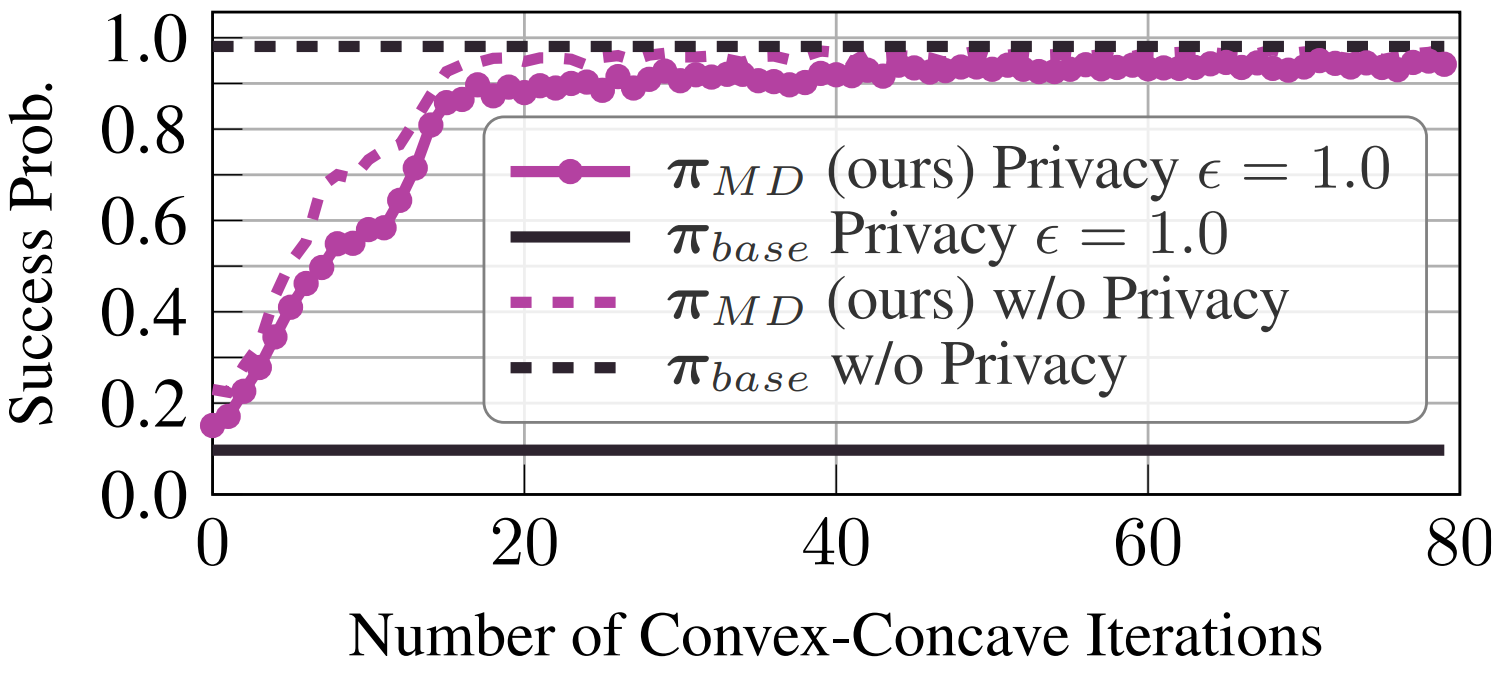
Privacy-aware multiagent systems must protect agents’ sensitive data while simultaneously ensuring that agents accomplish their shared objectives. Towards this goal, we propose a framework to privatize inter-agent communications in cooperative multiagent decision-making problems. More specifically, we apply a differential privacy mechanism to privatize agents’ communicated symbolic state trajectories, and analyze tradeoffs between the strength of privacy and the team’s performance. For a given level of privacy, this tradeoff is shown to depend critically upon the total correlation among agents’ state-action processes. We use this analysis to develop algorithms to synthesize policies that are robust to privacy by reducing the value of the total correlation.
Physics-Informed Kernel Embeddings: Integrating Prior System Knowledge with Data-Driven Control
Adam J. Thorpe*, Cyrus Neary*, Franck Djeumou*, Meeko M. K. Oishi, and Ufuk Topcu
The IEEE American Control Conference (ACC) 2024.
* indicates equal contribution.
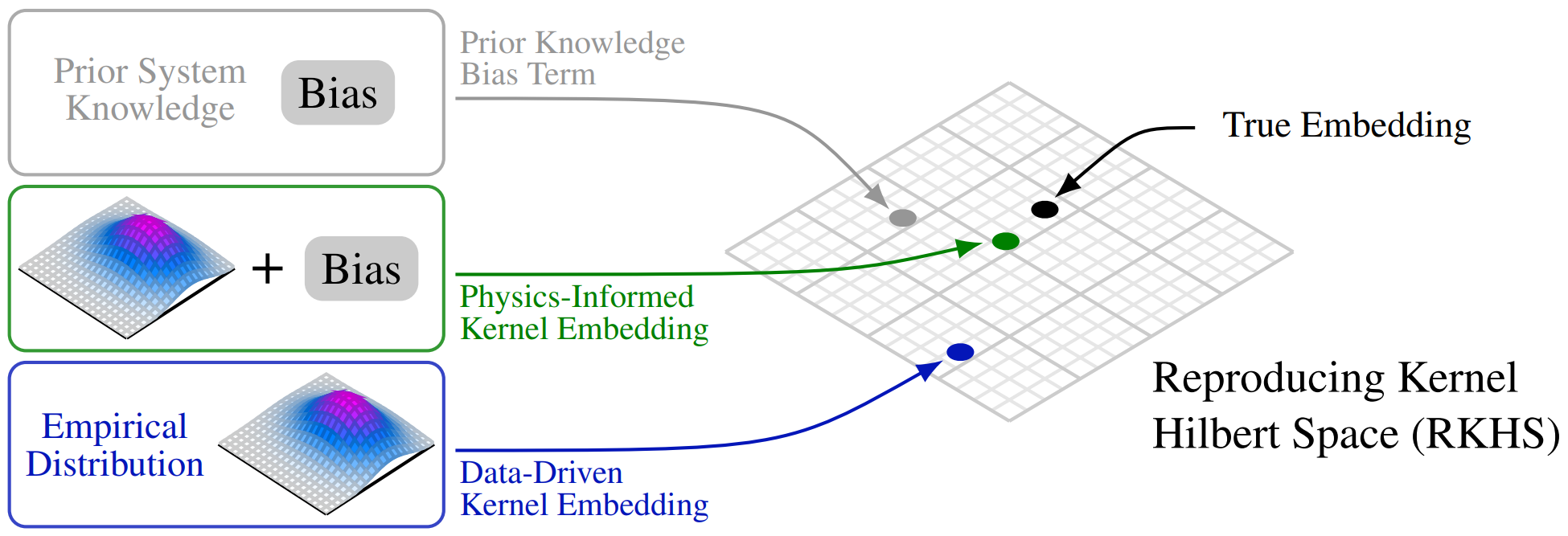
Data-driven control algorithms use observations of system dynamics to construct an implicit model for the purpose of control. However, in practice, data-driven techniques often require excessive sample sizes, which may be infeasible in real-world scenarios where only limited observations of the system are available. Furthermore, purely data-driven methods often neglect useful a priori knowledge, such as approximate models of the system dynamics. We present a method to incorporate such prior knowledge into data-driven control algorithms using kernel embeddings, a nonparametric machine learning technique based in the theory of reproducing kernel Hilbert spaces. We demonstrate an application of our method to control through a target tracking problem with nonholonomic dynamics, and on spring-mass-damper and F-16 aircraft state prediction tasks.
Verifiable and Compositional Reinforcement Learning Systems
Cyrus Neary, Christos Verginis, Murat Cubuktepe, and Ufuk Topcu
The International Conference on Automated Planning and Scheduling (ICAPS) 2022.
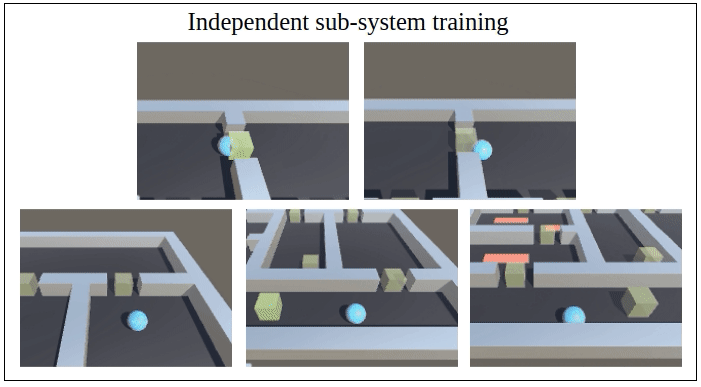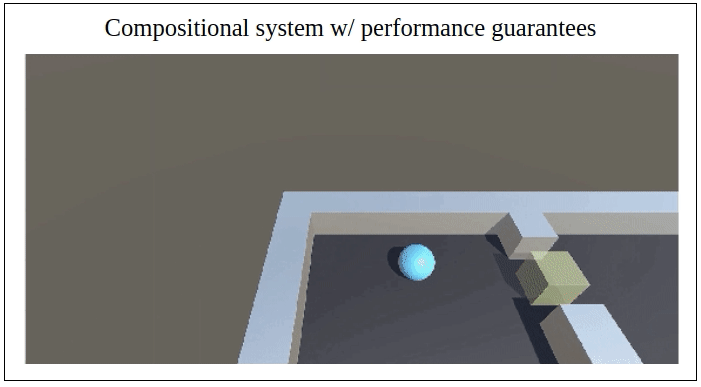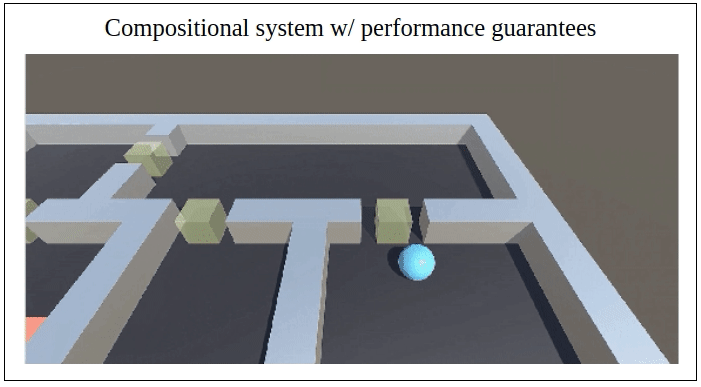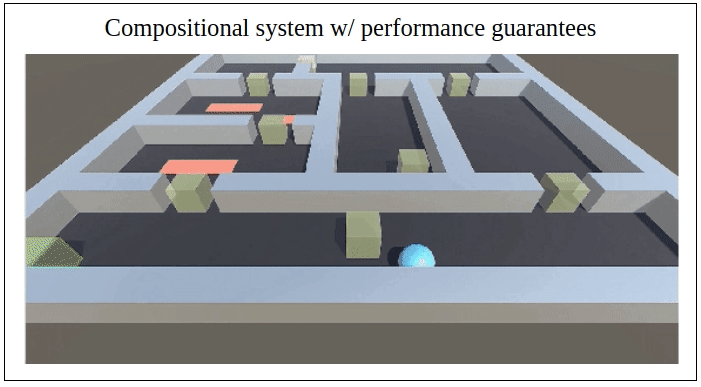
We propose a framework for verifiable and compositional reinforcement learning (RL) in which a collection of RL sub-systems – each of which learns to accomplish a separate sub-task – are composed to achieve an overall task. By defining interfaces between the sub-systems, the framework enables automatic decompositons of task specifications, e.g., reach a target set of states with a probability of at least 0.95, into individual sub-task specifications, i.e. achieve the sub-system’s exit conditions with at least some minimum probability, given that its entry conditions are met. This in turn allows for the independent training and testing of the sub-systems; if they each learn a policy satisfying the appropriate sub-task specification, then their composition is guaranteed to satisfy the overall task specification.
Read More | Paper | Poster | Code
Franck Djeumou*, Cyrus Neary*, Eric Goubault, Sylvie Putot, and Ufuk Topcu
The International Joint Conferences on Artificial Intelligence (IJCAI) 2022.
* indicates equal contribution.
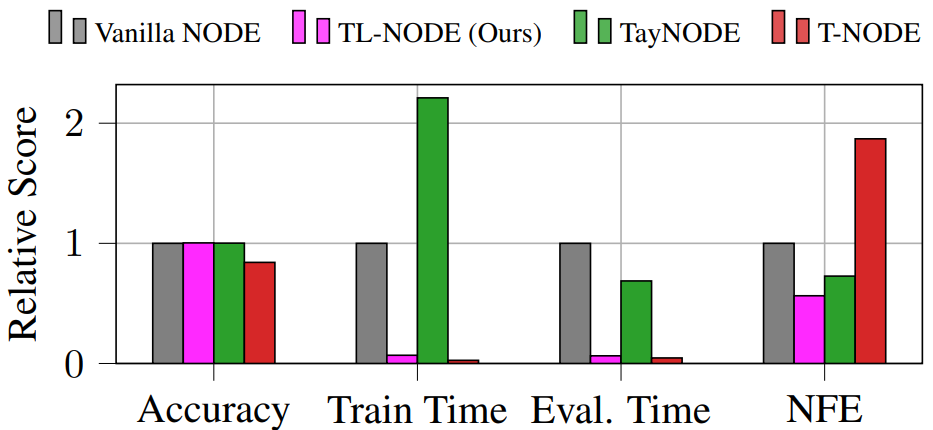
We accelerate the training and evaluation of Neural Ordinary Differential Equations (NODEs) by proposing a data-driven approach to their numerical integration. A suite of numerical experiments – including modeling dynamical systems, image classification, and density estimation – demonstrate that Taylor-Lagrange NODEs can be trained more than an order of magnitude faster than state-of-the-art approaches, without any loss in performance.
Read More | Paper | Poster | Code
Planning Not to Talk: Multiagent Systems that are Robust to Communication Loss
Mustafa O. Karabag*, Cyrus Neary*, and Ufuk Topcu
The International Conference on Autonomous Agents and Multiagent Systems (AAMAS) 2022.
* indicates equal contribution.
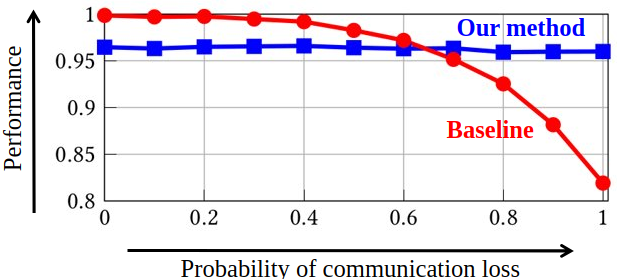
In a cooperative multiagent system, a collection of agents executes a joint policy in order to achieve some common objective. The successful deployment of such systems hinges on the availability of reliable inter-agent communication. However, many sources of potential disruption to communication exist in practice – such as radio interference, hardware failure, and adversarial attacks. In this work, we develop joint policies for cooperative multiagent systems that are robust to potential losses in communication. Numerical experiments show that the proposed minimum-dependency policies require minimal coordination between the agents while incurring little to no loss in performance.
Neural Networks with Physics-Informed Architectures and Constraints for Dynamical Systems Modeling
Franck Djeumou*, Cyrus Neary*, Eric Goubault, Sylvie Putot, and Ufuk Topcu
The Learning for Dynamics and Control Conference (L4DC) 2022.
* indicates equal contribution.
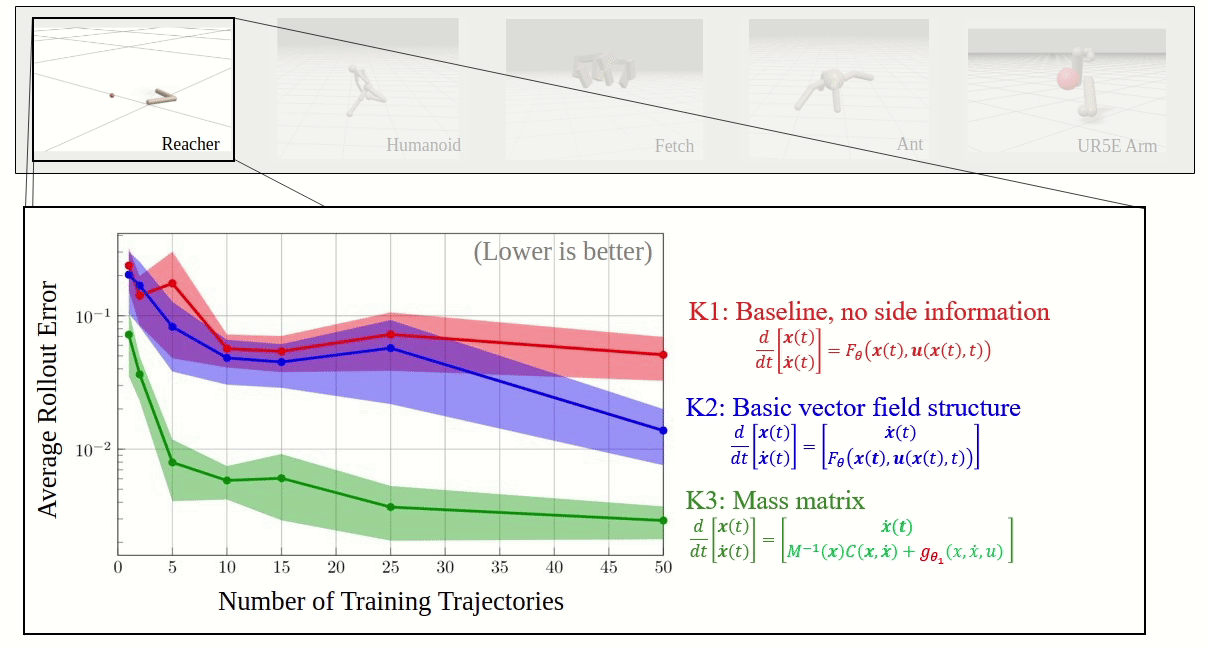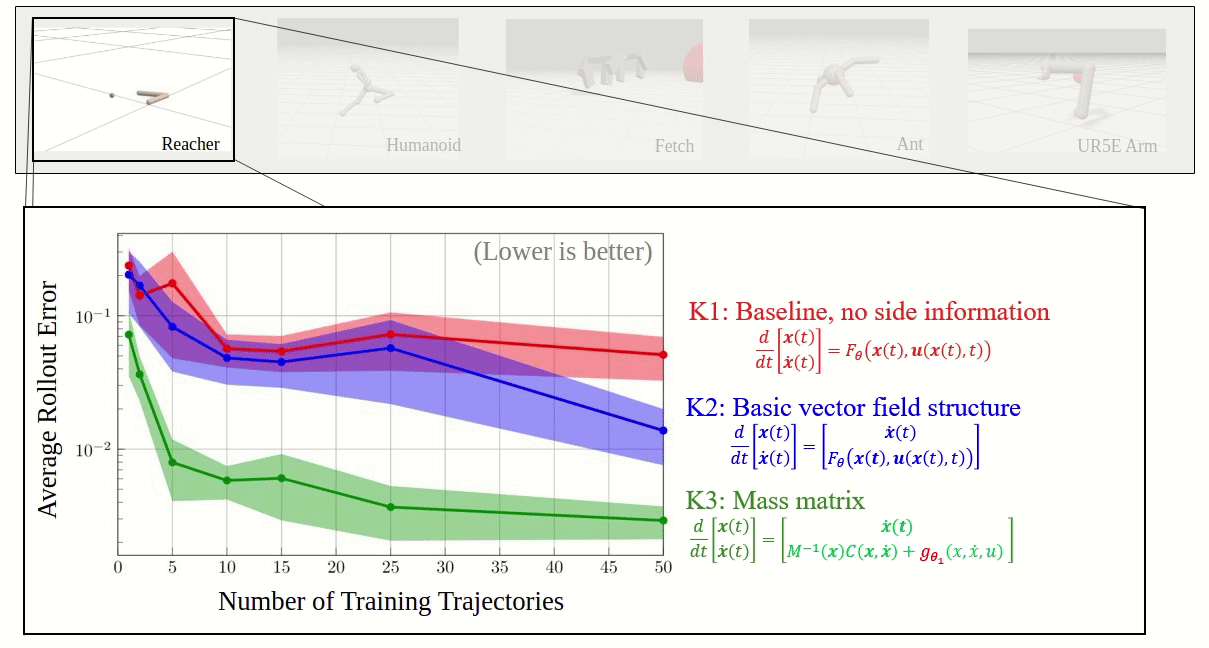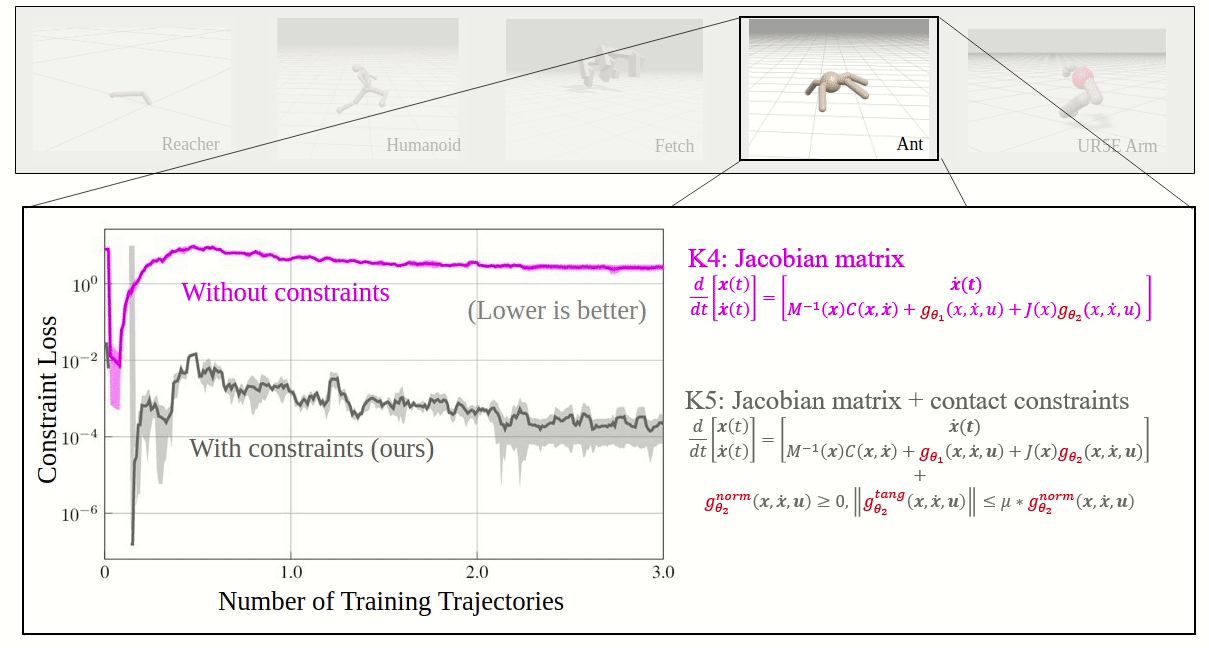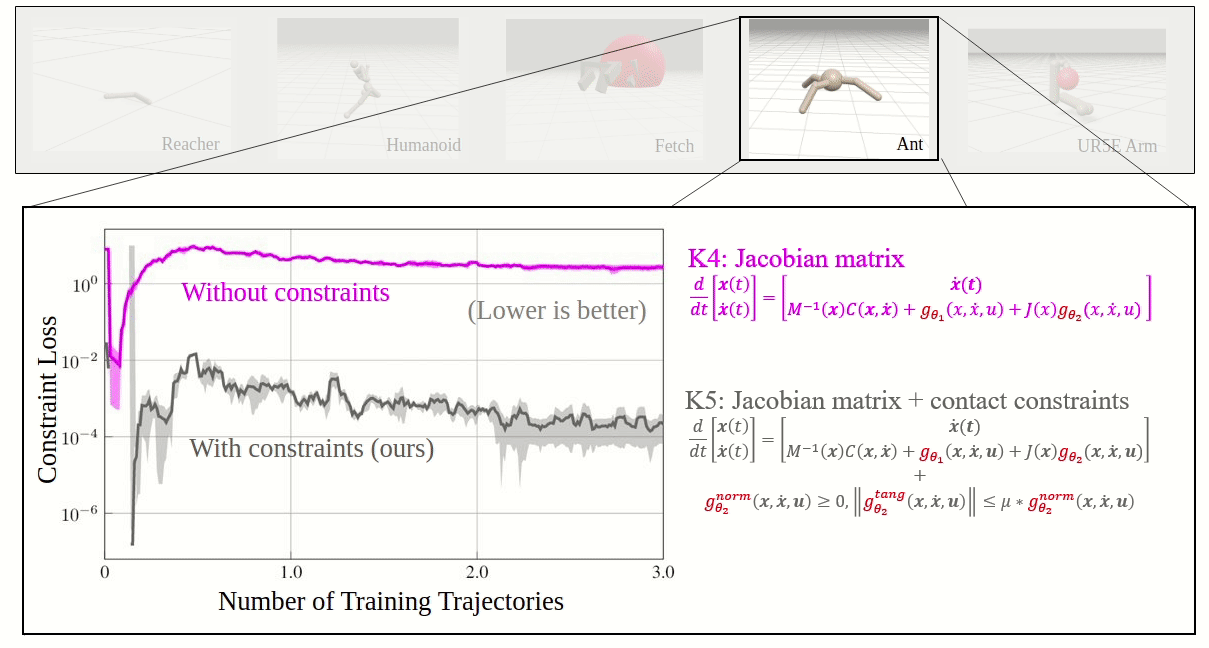
Effective inclusion of physics-based knowledge into deep neural network models of dynamical systems can greatly improve data efficiency and generalization. We accordingly develop a framework to learn dynamics models from trajectory data while incorporating a-priori system knowledge as inductive bias. More specifically, the proposed framework uses physics-based side information to inform the structure of the neural network itself, and to place constraints on the values of the outputs and the internal states of the model. By exploiting a-priori system knowledge during training, the proposed approach learns to predict the system dynamics two orders of magnitude more accurately than a baseline approach that does not include prior knowledge, given the same training dataset.
Read More | Paper | Poster | Code
Multiscale Heterogeneous Optimal Lockdown Control for COVID-19 Using Geographic Information
Cyrus Neary, Murat Cubuktepe, Niklas Lauffer, Xueting Jin, Alexander J. Phillips, Zhe Xu, Daoqin Tong, and Ufuk Topcu
Scientific Reports.
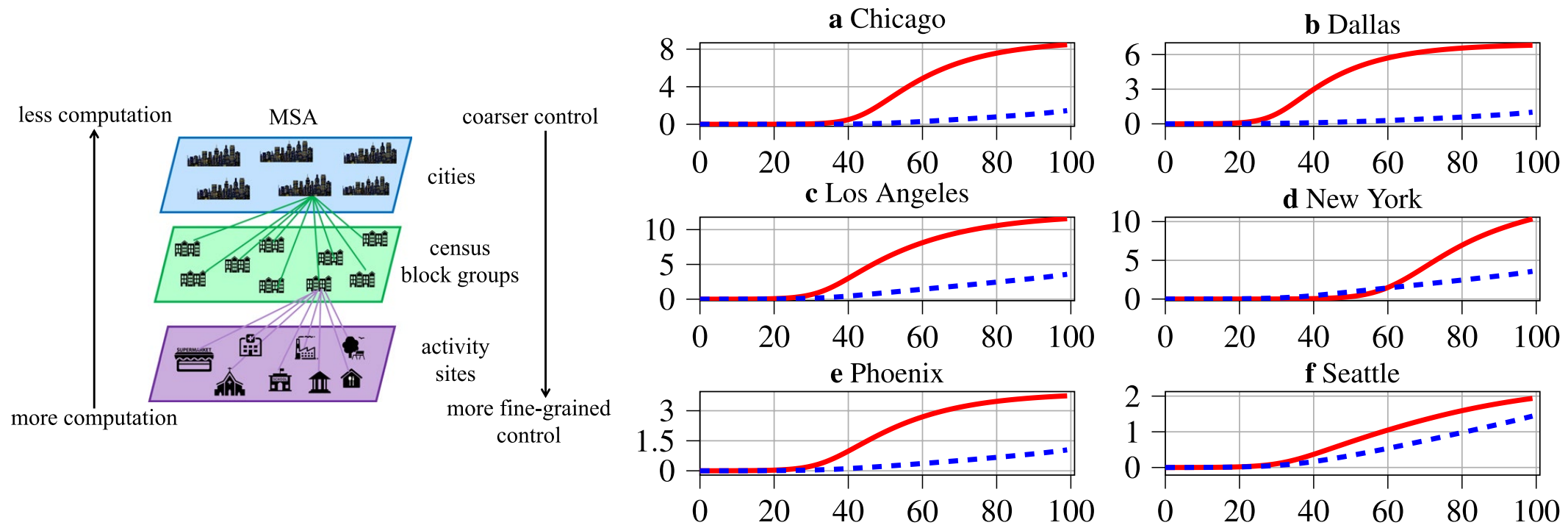
We study the problem of synthesizing lockdown policies—schedules of maximum capacities for different types of activity sites—to minimize the number of deceased individuals due to a pandemic within a given metropolitan statistical area (MSA) while controlling the severity of the imposed lockdown. To synthesize and evaluate lockdown policies, we develop a multiscale susceptible, infected, recovered, and deceased model that partitions a given MSA into geographic subregions, and that incorporates data on the behaviors of the populations of these subregions. This modeling approach allows for the analysis of heterogeneous lockdown policies that vary across the different types of activity sites within each subregion of the MSA. We formulate the synthesis of optimal lockdown policies as a nonconvex optimization problem and we develop an iterative algorithm that addresses this nonconvexity through sequential convex programming.
Reward Machines for Cooperative Multi-Agent Reinforcement Learning
Cyrus Neary, Zhe Xu, Bo Wu, and Ufuk Topcu
The International Conference on Autonomous Agents and Multiagent Systems (AAMAS) 2021.
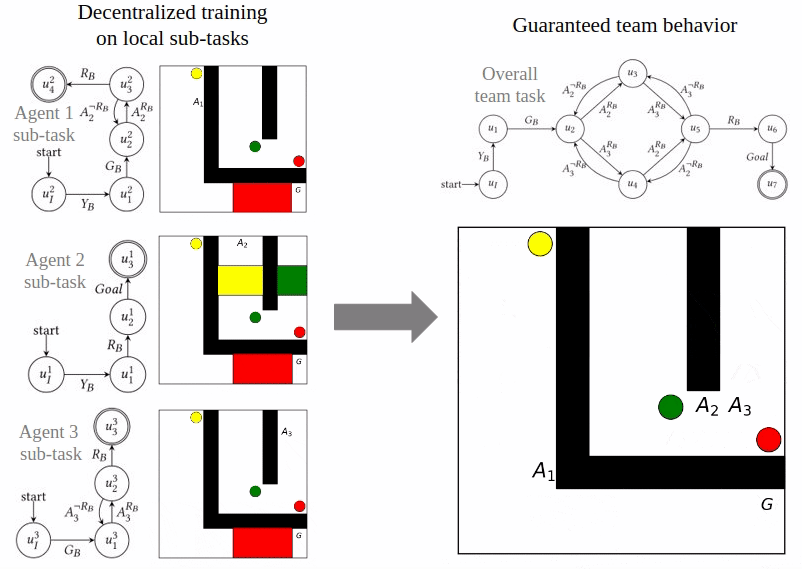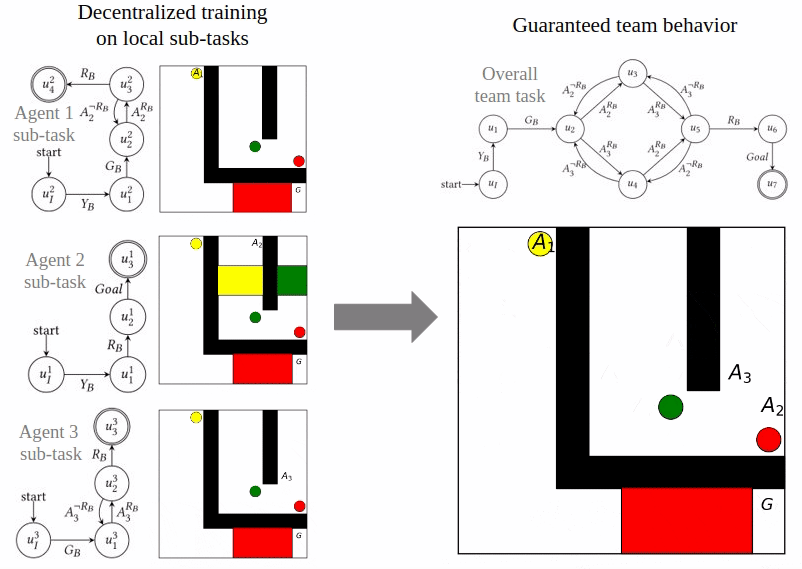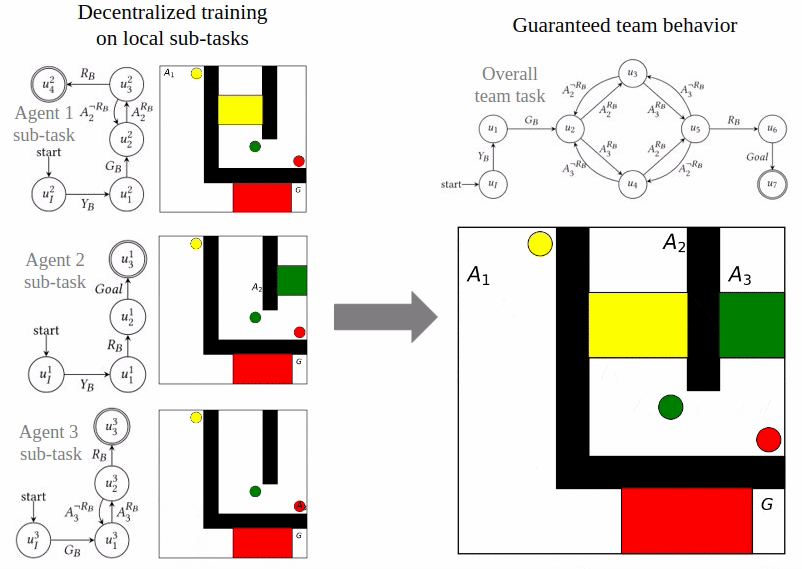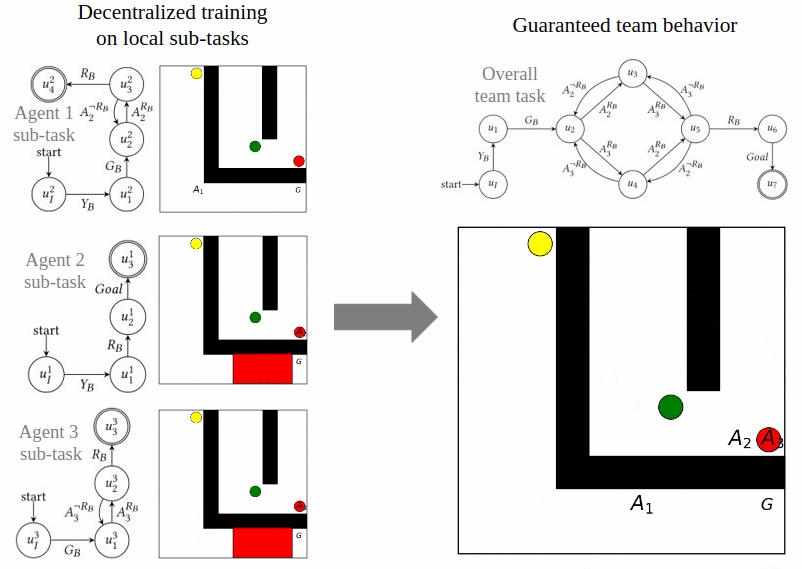
In cooperative multi-agent reinforcement learning, a collection of agents learns to interact in a shared environment to achieve a common goal. We propose the use of reward machines (RMs) to encode the team’s task, which allows the team-level task to be automatically decomposed into sub-tasks for individual agents. We present algorithmically verifiable conditions guaranteeing that distributed completion of the sub-tasks leads to team behavior accomplishing the original task. This framework for task decomposition provides a natural approach to decentralized learning: agents may learn to accomplish their sub-tasks while observing only their local state and abstracted representations of their teammates. We accordingly propose a decentralized Q-learning algorithm and demonstrate its superior sample complexity through two numerical experiments involving three agents and ten agents, respectively.
Read More | Paper | Presentation | Slides | Code
Smooth Convex Optimization Using Sub-Zeroth-Order Oracles
Mustafa O. Karabag, Cyrus Neary, and Ufuk Topcu
The AAAI Conference on Artificial Intelligence (AAAI) 2021.
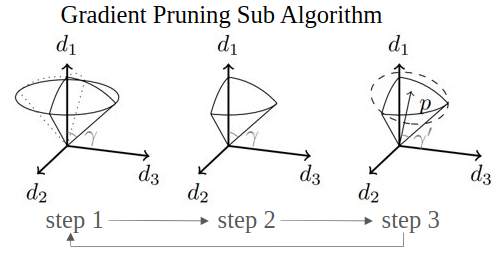
We present an algorithm to minimize smooth, Lipschitz, convex functions over a compact, convex sets using sub-zeroth-order oracles: an oracle that outputs the sign of the directional derivative for a given point and a given direction, an oracle that compares the function values for a given pair of points, and an oracle that outputs a noisy function value for a given point. We show that the sample complexity of optimization using these oracles is polynomial in the relevant parameters. We also give an algorithm for the noisy-value oracle that incurs sublinear regret in the number of queries and polynomial regret in the number of dimensions.