Verifiable and Compositional Reinforcement Learning Systems
Cyrus Neary, Christos Verginis, Murat Cubuktepe, and Ufuk Topcu
The International Conference on Automated Planning and Scheduling (ICAPS) 2022.
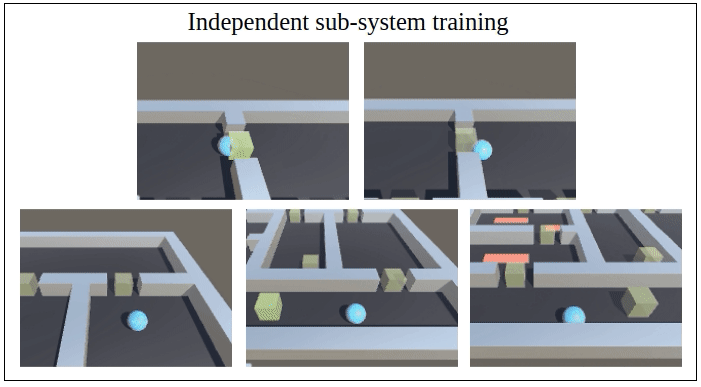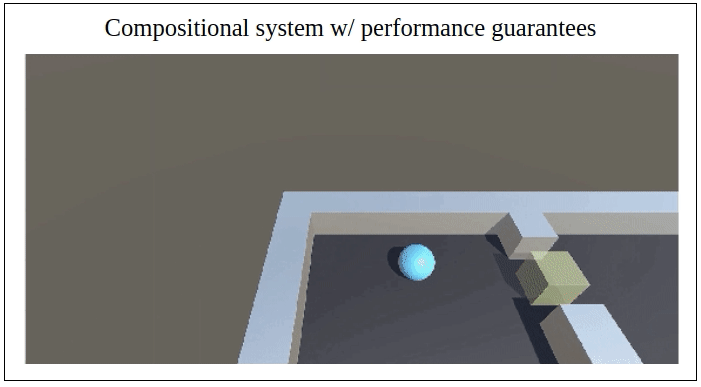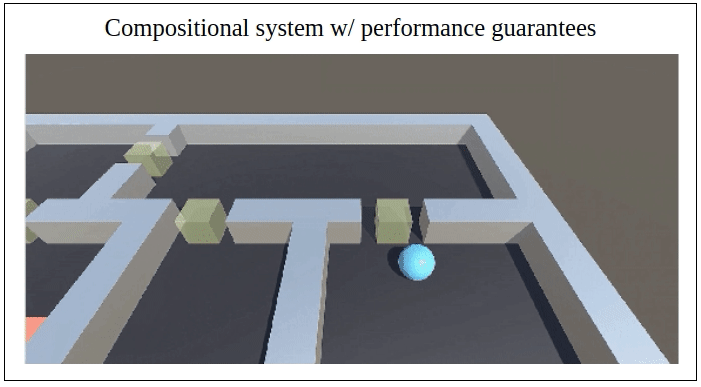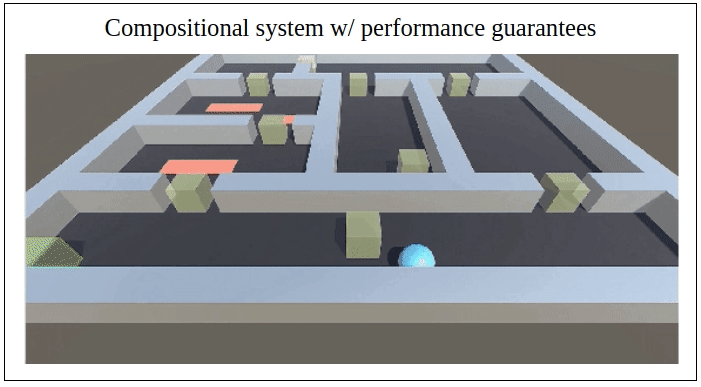
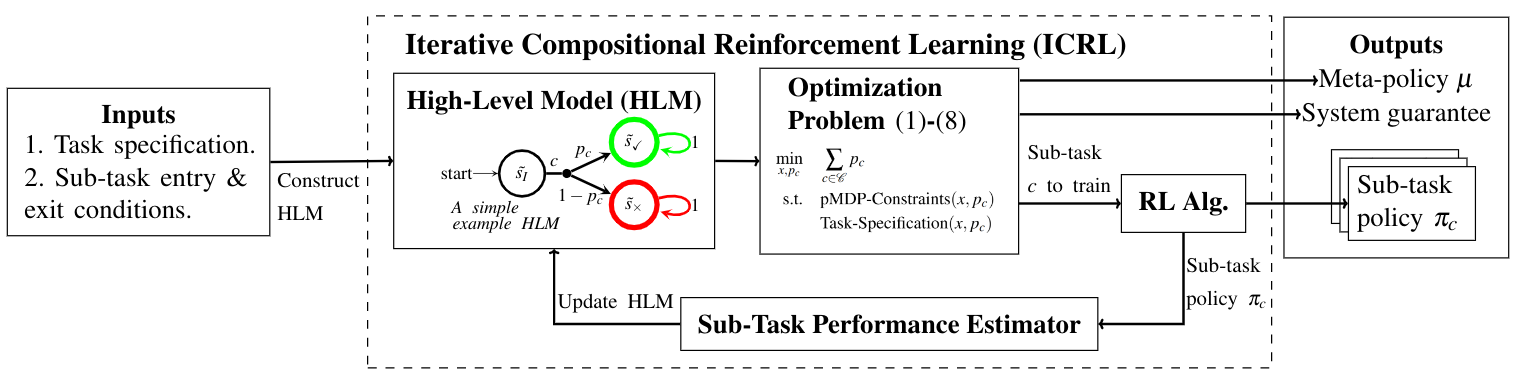
Abstract: We propose a novel framework for verifiable and compositional reinforcement learning (RL) in which a collection of RL sub-systems, each of which learns to accomplish a separate sub-task, are composed to achieve an overall task. The framework consists of a high-level model, represented as a parametric Markov decision process (pMDP) which is used to plan and to analyze compositions of sub-systems, and of the collection of low-level sub-systems themselves. By defining interfaces between the sub-systems, the framework enables automatic decompositons of task specifications, e.g., reach a target set of states with a probability of at least 0.95, into individual sub-task specifications, i.e. achieve the sub-system’s exit conditions with at least some minimum probability, given that its entry conditions are met. This in turn allows for the independent training and testing of the sub-systems; if they each learn a policy satisfying the appropriate sub-task specification, then their composition is guaranteed to satisfy the overall task specification. Conversely, if the sub-task specifications cannot all be satisfied by the learned policies, we present a method, formulated as the problem of finding an optimal set of parameters in the pMDP, to automatically update the sub-task specifications to account for the observed shortcomings. The result is an iterative procedure for defining sub-task specifications, and for training the sub-systems to meet them. As an additional benefit, this procedure allows for particularly challenging or important components of an overall task to be determined automatically, and focused on, during training. Experimental results demonstrate the presented framework’s novel capabilities. A collection of RL sub-systems are trained, using proximal policy optimization algorithms, to navigate different portions of a labyrinth environment. A cross-labyrinth task specification is then decomposed into sub-task specifications. Challenging portions of the labyrinth are automatically avoided if their corresponding sub-systems cannot learn satisfactory policies within allowed training budgets. Other unnecessary sub-systems are not trained at all. The result is a compositional RL system that efficiently learns to satisfy its task specification.